
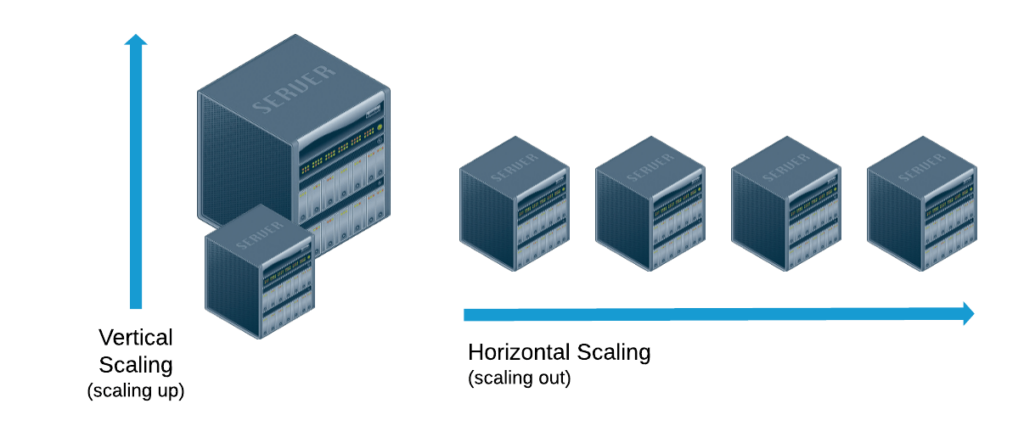
Horizontalno i vertikalno skaliranje
Nedavno smo održali radionicu pod nazivom ‘Horizontalno i vertikalno skaliranje’ koju je vodio naš developer Danijel Jakovac. U ovoj radionici upoznali smo se s prednostima i nedostatcima horizontalnog i vertikalnog skaliranja te kada koristiti koji od ova dva načina.
Pregled sadržaja
- Što je skaliranje i zbog čega je važno?
- Vertikalno skaliranje
- Prednosti vertikalnog skaliranja
- Nedostaci vertikalnog skaliranja
- Horizontalno skaliranje
- Prednosti horizontalnog skaliranja
- Nedostaci horizontalnog skaliranja
Što je skaliranje i zbog čega je važno?
Kod većine aplikacija, broj zahtjeva i korisnika mijenjat će se tijekom vremena. Zbog toga će sustav biti pod dodatnim opterećenjem i zahtijevati više resursa. Skaliranje podrazumijeva prilagodbu arhitekture i povećanje određenih resursa kako bi sustav mogao obraditi sve zahtjeve u prihvatljivom vremenu, omogućujući kontinuirani rast aplikacije i dolazak novih korisnika. U razvoju aplikacija postoje dva načina koja možemo koristiti: horizontalno i vertikalno skaliranje.
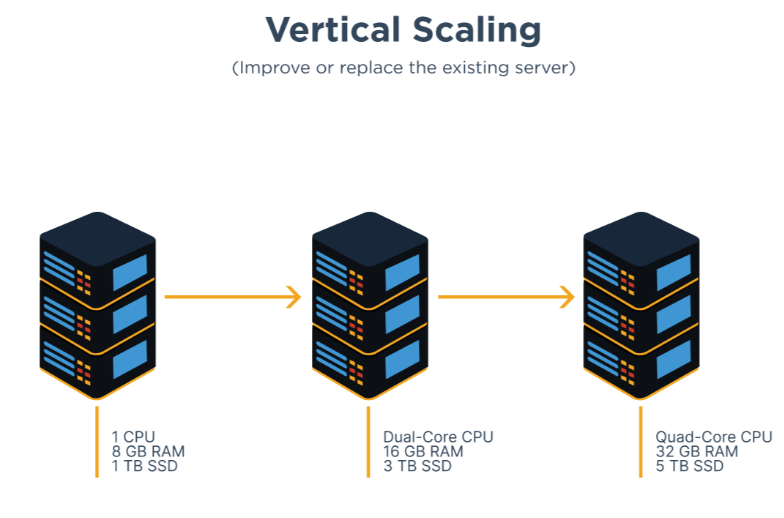
Vertikalno skaliranje
Vertikalno skaliranje predstavlja nadogradnju postojećih resursa kako bi sustav mogao obrađivati veću količinu podataka. To je primjerice dodavanje RAM memorije, ugradnja boljeg procesora i slično. Kod vertikalnog skaliranja podaci se nalaze na jednoj bazi podataka.
Prednosti
- Jednostavno upravljanje resursima – brzina obrade podataka povećava se nadogradnjom komponenti, stoga nemamo dodatnih promjena u kodu koje bi mogle povećati kompleknost upravljanja resursima i nadogradnje aplikacije.
- Niža cijena nadogradnje kod aplikacija manje ili srednje veličine – najveći trošak kod vertikalnog skaliranja je cijena komponenti. Samim time nadogradnja komponetni može koštati znatno manje od vremena uloženog u promjenu strukture koda.
Nedostatci
- Ograničena skalabilnost – postoji granica snage i performansi u komponentama. Čak i nakon ugrađivanja najboljih kompnenti, uvijek postoji mogućnost da ni te komponente neće biti dovoljne za obradu zahtjeva i podataka.
- SPF (Single point of failure) – cijela aplikacija i svi podaci nalaze se na jednom poslužitelju. U slučaju bilo kakvog kvara ili greške, niti jedan od klijenata neće biti u mogućnosti pristupiti aplikaciji.
- Zastoj (downtime) pri nadogradnji – u procesu nadogradnje komponenti, aplikacija je nedostupna na određeno vrijeme.
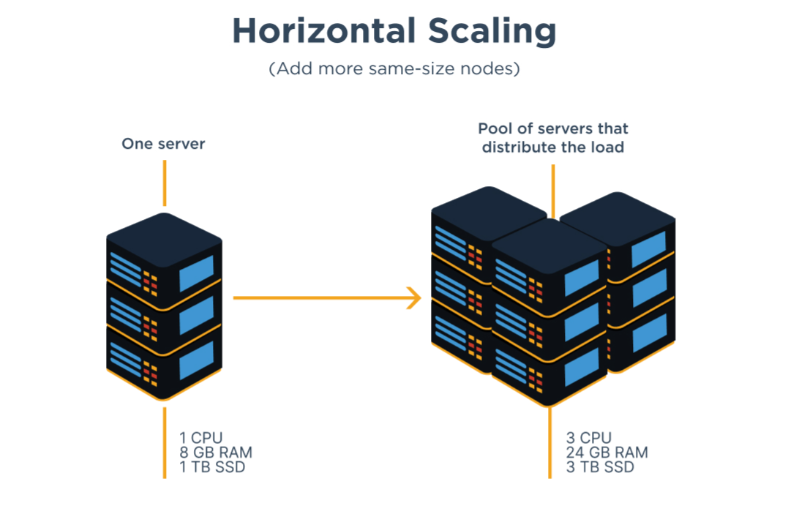
Horizontalno skaliranje
Horizontalno skaliranje predstavlja dodavanje više poslužitelja u sustav i podjelu baze podataka na više poslužitelja kako bi se povećao kapacitet obrade podataka i zahtjeva, te otpornost sustava na opterećenje.
Neke od metoda horizontalnog skaliranja su sljedeće:
- Raspodjela opterećenja (Load Balancing) – korištenje load balancera za raspodjelu zahtjeva među poslužiteljima.
- Raspodjela baze podataka (Database Sharding) – raspodjela podataka na manje dijelove (‘shardove’) i na više poslužitelja, čime se smanjuje opterećenje pojedinačne instance baze.
- Replikacija baze podataka (Database Replication) – stvaranje kopija baze podataka na više servera za poboljšanje čitanja i otpornosti.
- Mikroservisi – umjesto jednog monolitnog sustava, aplikacija se razbija na više manjih servisa i samim time omogućuje skaliranje svakog servisa neovisno.
Prednosti
- Neograničena skalabinost – umjesto nadogradnje jednog poslužitelja pojedinačno, možemo dodati neograničen broj poslužitelja sa istim komponentama.
- Nema zastoja pri nadogradnji sustava (zero to no downtime) – ukoliko su sustav i njegova struktura dobro implementirani, neće doći do zastoja pri nadogradnji sustava obzirom da se zahtjevi mogu rasporediti na više različitih poslužitelja.
- Jefitnija nadogradnja sustava u velikim aplikacijama
- Bolje performanse – s obzirom da su podaci i zahtjevi distribuirani, obrada podataka u velikim aplikacijama je puno brža. Sustav, naime, umjesto obrade velike količine podataka iz jedne instance baze, obrađuje puno manji skup podataka koji se nalazi na specifičnom distribuiranom poslužitelju.
Nedostatci
- Složenost infrastrukture – distribuiranje podataka na više poslužitelja dodaje novu razinu složenosti u kodu. To znači da je pri implementaciji novih i održavanju starih značajki aplikacije potrebno je paziti ispravnu distribuciju podataka.
- Problemi s konzistentnoščću podataka – u distribuiranim bazama podataka često se mora birati između konzistentnosti, dostupnosti i tolerancije na particije (CAP teorem).
- Složeniji debugging – podaci i zahtjevi su podijeljeni na više poslužitelja zbog čega imamo više logova, te je potrebno više vremena kako bi se otkrilo gdje je došlo do određene greške.
- Veći troškovi pri postavljanju infrastrukture – dizajniranje i implementiranje distribuiranog sustava može koštati znatno više od nadogradnje samih komponenti.